
Tuesday, 16 June 2026 09:00 AM
Product Announcements
Built as an audio-based dubbing pipeline rather than a conventional text-to-speech system, TailorDub preserves the timing, emotion, and intonation of the original performance - with core techniques detailed in three academic papers presented at Korea's leading computer science conferences
LOS ANGELES, CA / ACCESS Newswire / June 16, 2026 / AI media tech company Studio Freewillusion Inc. today unveiled new performance results and technical details for TailorDub, its AI-powered automatic dubbing technology. In a qualitative evaluation conducted with an independent panel of 50 professional AI video creators rating outputs on a five-point scale, TailorDub outperformed a global AI dubbing SaaS platform across every category measured - including a roughly 48% advantage in speech-pacing stability.
Unlike conventional dubbing tools built on text-to-speech (TTS), TailorDub is designed as an audio-based dubbing pipeline that works directly from the original audio track. The system separates the audio from the source content, analyzes the speech segments, then generates and aligns translated dialogue to fit those segments. It then renders voices that carry the original emotion and intonation, and recombines them with the original sound mix. Rather than simply outputting translated speech, TailorDub re-engineers the dubbed audio around the speech flow and acoustic environment of the original video.
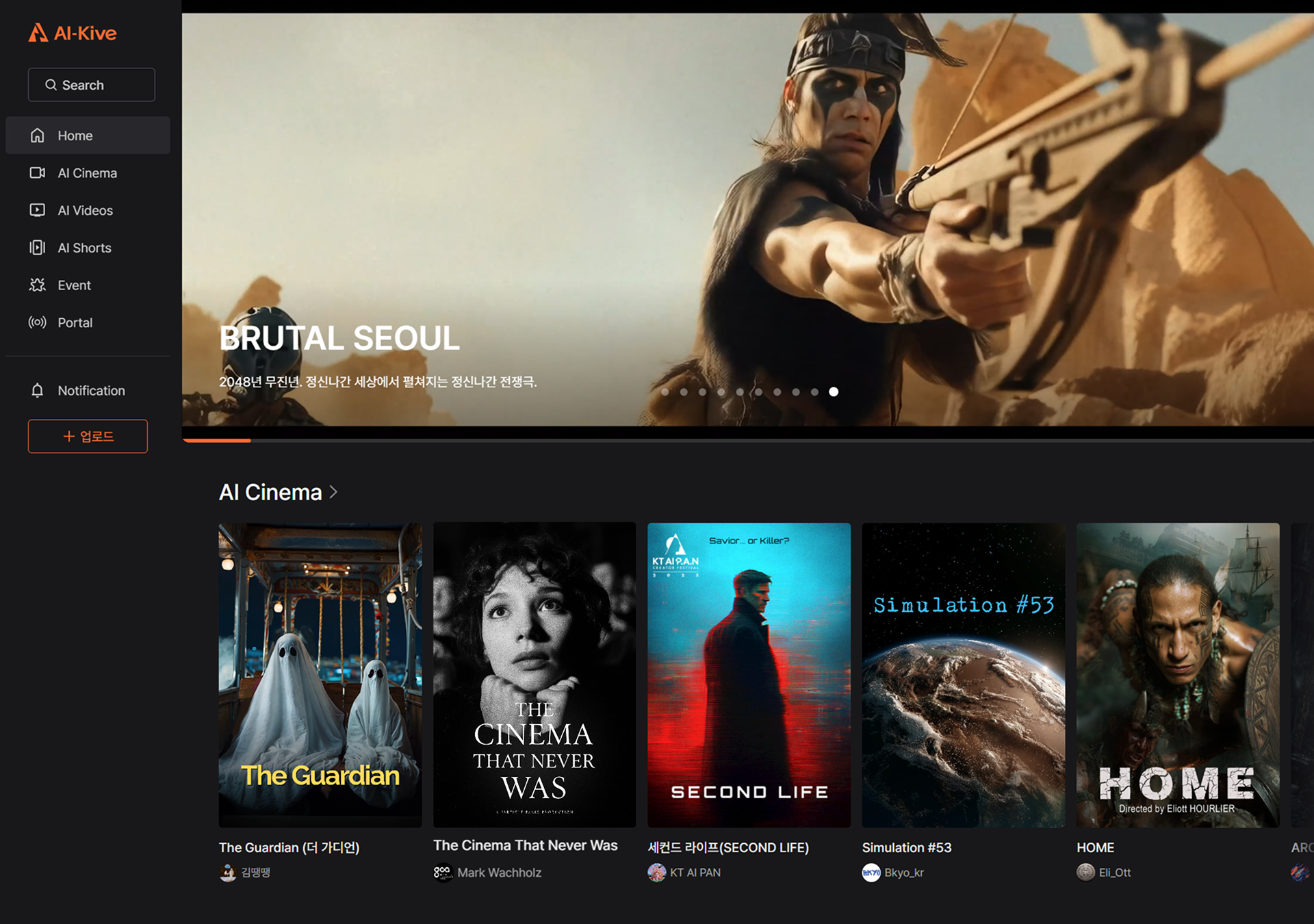
The main page of the AI-Kive website, Studio Freewillusion's AI content platform and the first home for its new TailorDub dubbing technology. (Image: Studio Freewillusion)
"Most AI dubbing today is still focused on delivering information. It can produce clear pronunciation and natural-sounding voices, but it often fails to capture the emotion, tone, and pacing of the original performance," said Dongwook Cho, head of Studio Freewillusion's U.S. operations. "With TailorDub, we focused on faithfully recreating the original performance. The system generates dubbed dialogue that follows the original performer's tone, pacing, and emotion. That is what creates the difference in immersion viewers can feel."
Beyond voice fidelity, TailorDub also tackles a separate challenge: timing. Because translated sentences differ in length across languages, conventional TTS dubbing often produces speech that rushes, drags, or drifts out of sync with the picture. TailorDub aligns timing to the original speech segments to reduce these mismatches, and an AI agent reviews each translation - retranslating where needed - so the dubbed dialogue does not disrupt the flow of a scene. On the audio side, the system preserves background music and sound effects from the original mix, maintaining the overall sonic atmosphere even in content where dialogue, music, and effects overlap.

A before-and-after example of TailorDub, which converts Korean-language video into natural English. (Image: Studio Freewillusion)
In the evaluation, the largest gap appeared in speech-pacing stability, where TailorDub scored 3.62 out of 5 versus 2.44 for the competing platform - approximately 48% higher. The metric directly reflects how well a system handles sentence-length differences after translation. TailorDub also scored 26.9% higher in naturalness of speaking style and 23.0% higher in immersion-rated speech-sync quality.
"Speech-pacing stability is where automated dubbing usually breaks down, because Korean and English sentences rarely take the same amount of time to say," Cho added. "Having independent professional creators score us 48% ahead on that exact metric tells us the pipeline is solving the right problem."
The technology is also backed by academic research. The company has presented three related papers at Korea's premier computer science conferences. At the 2025 Korea Software Congress (KSC), it introduced "FLUID: A Training-Free Iterative Framework for Fluent and Length-Uniform AI Dubbing," which achieves fluency and consistent speech duration without additional model training. At the 2026 Korea Computer Congress (KCC), it presented "SLATE: Slot-Preserving Length-Aware Translation Editing for Korean AI Dubbing," which adjusts translation length while preserving core units of meaning, and "AFTER: Audio-Feedback Translation and Expressive Refinement for Duration-Synchronized Automatic Video Dubbing," which uses audio feedback to synchronize speech duration.
About Studio Freewillusion
Studio Freewillusion is an AI media tech company that combines generative AI with VFX across the full content lifecycle - from development and production through post-production and global distribution, extending to its AI content platform, AI-Kive. The company established its U.S. subsidiary in Los Angeles in February 2026 to deepen collaboration with the North American entertainment industry, and its proprietary AFX (AI + VFX) pipeline is currently used in post-production on Hollywood feature films. Its production work spans TV commercials, film, and animation, and its recognition includes the Grand Prize and Audience Award at the Dubai International AI Film Festival, selection for Google for Startups Accelerator: AI First, and a commendation from Korea's Ministry of Science and ICT.
Media Contact
Studio Freewillusion Los Angeles Office
Email: [email protected]
Website: www.studiofreewillusion.com
SOURCE: Studio Freewillusion